1 Introduction
Since the beginning of the research on speech recognition in the 1950s, after decades of development, it has reached a certain height, and some have moved from the laboratory to the market, such as some toys, password voice input in certain departments, etc., with the DSP and The development of application-specific integrated circuit technology, fast Fourier transform and recent research on embedded operating systems have made it possible to identify specific persons, especially those with low computational complexity. Therefore, the research on the application of specific person speech recognition technology in car control is very promising.
2 Specific person voice recognition method
At present, commonly used speaker recognition methods include template matching method, statistical modeling method, and connectionism method (that is, artificial neural network implementation). Taking into account the amount of data, real-time and recognition rate, the author uses a method based on the combination of vector quantization and hidden Markov model (HMM).
The speaker recognition system is mainly composed of a speech feature vector extraction unit (front-end processing), a training unit, a recognition unit, and a post-processing unit. The system configuration is shown in FIG. 1.
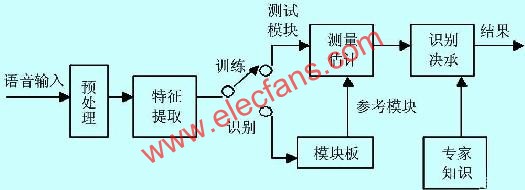
Figure 1 System configuration
It can also be seen from the above figure that each driver must enter his own voice into the system after purchasing the car, which is the training process. Of course, it is best to be quiet and reach a certain number of times. From now on, you can use this system during driving.
The so-called pre-processing refers to the special processing of the speech signal: pre-emphasis, frame processing. The purpose of pre-emphasis is to raise the high-frequency part, so that the signal spectrum becomes flat, in order to facilitate spectrum analysis or channel parameter analysis. It is realized with a pre-emphasis digital filter with 6dB / octave boosted high-frequency characteristics. Although the speech signal is non-stationary and time-varying, it can be considered as local short-term stationary. Therefore, voice signal analysis is often processed in segments or frames.
2.1 Speech feature vector extraction unit
The fundamental problem in the design of speaker recognition systems is how to extract the basic characteristics of people from speech signals. Namely, the extraction of speech feature vectors is the basis of the entire speaker recognition system, which has an extremely important influence on the false rejection rate and false acceptance rate of speaker recognition. Unlike speech recognition, speaker recognition uses speaker information in the speech signal, regardless of the meaning of the words in the speech, which emphasizes the personality of the speaker. Therefore, a single speech feature vector is difficult to improve the recognition rate. The system uses cepstrum coefficients plus gene cycle parameters in speaker recognition, while only cepstrum coefficients are used in speech recognition of control commands. Among them, there are two kinds of commonly used cepstrum coefficients, namely LPC (linear prediction coefficient) and cepstrum parameters (LPCC), one is based on the MFLL (frequency cepstrum coefficient) parameter (Mel frequency spectrum coefficient) based on Mel scale.
For the extraction of LPCC parameters, you can first use the Durbin recursive algorithm, lattice algorithm or Schur recursive algorithm to find the LPC coefficients, and then find the LPC parameters. Suppose the LPC coefficient of the lth frame speech is αn, then the parameters of LPCC are ![]() 1 < n≤p
1 < n≤p
Where p is the order of LPCC coefficients, and k is the number of recurrences of LPCC coefficients.
Further research found that the introduction of first-order and second-order differential cepstrum can improve the recognition rate.
For the extraction of MPCC parameters, if the speech signal spectrum is divided into K frequency bands according to the Mel curve, and the energy of each frequency band is θ (Mk), then the MFCC parameter is  1 < n≤p
1 < n≤p
Through the experimental comparison of the influence of LPCC and MFCC parameters on the recognition rate, the author selects LPCC parameters and their first- and second-order differential cepstrum sparseness as the characteristic parameters.
There are many methods for pitch period estimation, mainly algorithms based on short-term autocorrelation function, algorithms based on short-time average amplitude difference function (AMDF), algorithms based on homomorphic signal processing and linear predictive coding. The author only introduces algorithms based on finding short-term autocorrelation functions.
Let Sw (n) be a windowed speech signal whose non-zero interval is 0 <n≤n-1. The autocorrelation function of Sw (n) is called the short-term autocorrelation function of S (n) of the speech signal, which is represented by Rw (l), that is, Rw (l) =  It can be seen that the short-term autocorrelation function is the largest at Rw (0) and has a large peak at each integer multiple of the pitch period. Choose a suitable window function (hamming window with a window length of 40ms) and a filter (bandwidth is 60 ~ 900Hz band-pass filter), as long as you find the position of the first maximum peak point of the autocorrelation function and calculate its distance from the zero point, you can estimate the pitch period.
It can be seen that the short-term autocorrelation function is the largest at Rw (0) and has a large peak at each integer multiple of the pitch period. Choose a suitable window function (hamming window with a window length of 40ms) and a filter (bandwidth is 60 ~ 900Hz band-pass filter), as long as you find the position of the first maximum peak point of the autocorrelation function and calculate its distance from the zero point, you can estimate the pitch period.
2.2 Training unit
The function of the training unit is to train the parameters collected in advance for each speaker to be recognized using a certain algorithm using a certain algorithm. Aiming at the different requirements of speaker recognition in automotive applications, the training unit is also divided into 2 parts: the training of speaker recognition and the training of recognition words.
For the training of speaker recognition part, train on the characteristics of the speaker, establish one or more sets of HMM models for each legal user, and use vector quantization (VQ) -based method to establish a VQ codebook for each legal user . The VQ codebook is designed using the LBG algorithm, and the initial codebook is set using the split method initial codebook.
Part 2 establishes multiple training samples, or term samples, for each isolated entry used in the control command, and estimates the HMM parameters (one or more sets) of the entry. A complete description of an HMM process includes: 2 model parameters N and M, and 3 sets of probability measures A, B, and π. For convenience, a complete model is usually expressed as follows: λ = (N, M, π, A, B), or simply: λ = (π, A, B). For the model parameters of each entry V, V = 1 ~ V, Baum-Welch re-estimation method can be used.
2.3 Identification unit
The function of the recognition unit is to recognize the speaker to be recognized and estimate the control command string to be recognized under certain judgment conditions using the HMM model parameters obtained through training and the measured pitch period of the speaker. The decision condition usually adopted for the parameters of the HMM model is the maximum posterior probability, which is realized by the Viterbi algorithm.
2.4 Post-processing unit
Make full use of the vocal tract parameters of each speaker and the probability distribution of each state duration in the entry to improve the recognition rate of the system.
3 Implementation of the system
Because the control commands of the car are a combination of limited entries and numeric strings, the recognition of these voice commands belongs to the recognition of small words of a specific person and the confirmation of speakers related to the text, regardless of the current DSP operation speed In terms of storage space, real-time recognition of these voice commands is entirely possible.
The block diagram of the recognition system is shown in the figure: in this system, the speech recognition part, which has very high requirements on computing power and storage unit, is completely completed by DSP.

Figure 2 Block diagram of the identification system
The function of the recognition system in the block diagram is to complete voice input, A / D conversion and recognition. The core part of the system uses TMS320VC5410. The reason is that its computing speed and storage space can meet the requirements. At the same time, some of its parallel computing hardware structures are also very suitable for various algorithms of speech recognition. The program and the HMM parameter table that has been trained offline and the corresponding dictionary are stored in In the program memory, the data memory stores the intermediate calculation data in the recognition process. The A / D chip uses TLC320AD50C, which contains A / D, D / A, low-pass filter and sample-and-hold circuit. The input of the analog voice signal is mainly through the microphone to ensure the security of the voice access control. The converted digital voice data is transmitted to the DSP in synchronous serial communication. As shown in Figure 2.
4 Conclusion
Voice-controlled cars are a trend in the future. At present, the application of voice technology to cars is only used in some toys, so it is conceivable that the field of voice technology for car control contains a considerable potential market.
Moreover, the speaker recognition technology has been developed to be applicable to the actual stage, but currently there are not many applications for speaker recognition. The author attempts to propose a scheme that is relatively easy to implement, and applies speaker recognition technology to practice. However, in practical applications, speaker recognition systems are faced with a common problem, that is, it is impossible to distinguish whether a pronunciation is live pronunciation or recording playback. In response to this phenomenon, the speaker recognition system proposed by the author can effectively prevent this from happening. When a speaker recognition system is specifically implemented, a random or other method may be used to generate the prompt text. Such as a random number string, so that the counterfeiter cannot record in advance, increasing the safety of driving.
Flexible Welding Cable,Insulated Middle Voltage Cable,Single Core Welding Cable,Insulated Flexible Welding Cable
Huayuan Gaoke Cable Co.,Ltd. , https://www.bjhygkcable.com